- AI Engineering
- Posts
- Open-source SQL-native memory engine for AI agents
Open-source SQL-native memory engine for AI agents
.. PLUS: OCR Arena - Playground for Testing OCR Models and VLMs
Sumanth P
November 25, 2025
In today’s newsletter:
Memori - Open-source SQL-native memory engine for AI agents
OCR Arena - Playground for Testing OCR Models and VLMs
Amphi ETL - Python-based visual tool for data transformation
Reading time: 3 minutes.
Memori is a memory layer that gives any LLM persistent, queryable memory using standard SQL databases.
Most agents forget everything once the session ends.
They can retrieve information, but they can’t retain or reuse context from previous interactions.
Memori solves this by extracting entities, relationships, and facts from conversations or tool calls, storing them in SQLite or Postgres, and injecting relevant context automatically when the agent needs it.
Key Features:
One-line integration - Works with OpenAI, Anthropic, LiteLLM, LangChain, and any LLM framework
SQL-native storage - Portable, queryable, and auditable memory in databases you control
80-90% cost savings - No expensive vector databases required
Zero vendor lock-in - Export your memory as SQLite and move anywhere
Intelligent memory - Automatic entity extraction, relationship mapping, and context prioritization
It's 100% Open Source
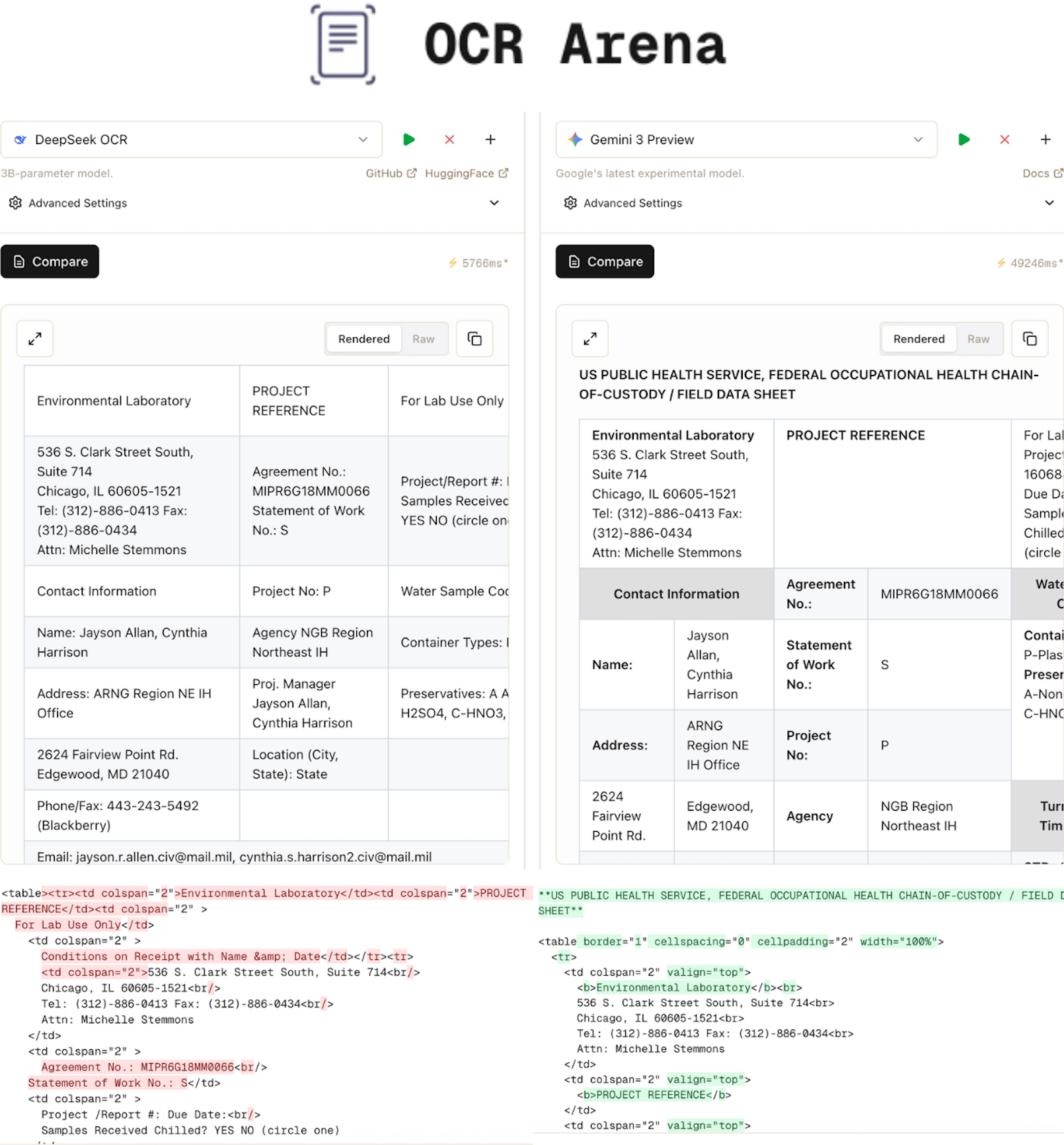
OCR Arena is an open playground to test OCR and VLM models on real documents.
Document processing is becoming a core part of many AI workflows, but evaluating OCR models / VLMs is still difficult.
Benchmarks rarely match real documents. The real test is how models handle real documents and edge cases.
OCR Arena solves this by letting you compare leading models in one place.
You can upload your files and test them against Gemini 3, dots.ocr, DeepSeek-OCR, GPT 5, and 10+ other popular OCR models.
On my tests, the difference was obvious.
DeepSeek-OCR lost structure and missed nested tables, while Gemini 3 preserved formatting, sub-sections, and cell boundaries with far better accuracy.
Here is what OCR Arena brings:
Compare OCR and VLM models side by side
Test PDFs, images, structured docs, tables, handwriting, and scanned pages
Visual diff to inspect formatting issues, table structure, and extraction accuracy
Transparent and unbiased model comparisons
Model leaderboard with public rankings
Amphi ETL is a low-code Python tool that lets you design and execute complete ETL workflows through a visual interface while generating clean, runnable Python code under the hood.
You can connect data sources, clean messy files, transform them with Python or DuckDB, and export the results in any format you need.
Key Features:
Visual Pipelines: Build, connect, and run ETL steps in a low-code environment.
Native Python Output: Generates reproducible Python code using pandas and DuckDB.
Integrated Runtime: Run pipelines locally or from JupyterLab with a single command.
Modular Components: Add custom data sources, transformations, or outputs as needed.
Low-Code, Production-Ready: Ideal for data prep, analysis, and workflow automation.
It helps you move faster from raw files to clean, structured data ready for analysis.

That’s a Wrap
That’s all for today. Thank you for reading today’s edition. See you in the next issue with more AI Engineering insights.
PS: We curate this AI Engineering content for free, and your support means everything. If you find value in what you read, consider sharing it with a friend or two.
Your feedback is valuable: If there’s a topic you’re stuck on or curious about, reply to this email. We’re building this for you, and your feedback helps shape what we send.
WORK WITH US
Looking to promote your company, product, or service to 160K+ AI developers? Get in touch today by replying to this email.