- AI Engineering
- Posts
- Clone Any Voice With Just 3 Seconds of Audio
Clone Any Voice With Just 3 Seconds of Audio
... PLUS: Train Gemma 4 with Reinforcement Learning
Sumanth P
April 17, 2026
In today's newsletter:
ADE Extract: Schema-Driven Extraction for Long, Complex Documents
VoxCPM: Tokenizer-Free TTS That Clones Any Voice
GRPO: Train Gemma 4 with Reinforcement Learning
Reading time: 5 minutes.
Traditional document extraction pipelines break on long and complex documents.
You process a 100-page contract. Split it into chunks. Extract data from each chunk separately. Stitch the results back together manually. A table spanning three pages comes back as three disconnected fragments. You write code to reconnect them. The next vendor's format is different. You write more code.
Your extraction pipeline ends up with more stitching code than actual extraction logic.
One supplier calls it "Payment Terms." Another calls it "Net 30." A third buries it in a footnote with no label. Your extraction schema can't handle the variation.
You maintain separate schemas per vendor. Or you build custom parsers. Or you give up and do it manually.
Schema drift breaks silently. A vendor changes their invoice format. Your pipeline keeps running but extracts wrong values.
LandingAI released the new ADE Extract API just to fix this. The full document gets processed in a single API call without chunking. A master schema handles all vendor format variations.
Here's how it works:
Schema Building API generates a master schema from sample documents. One schema handles all format variations.
Extract API applies that schema to new documents and returns structured JSON.
What makes it different:
Handles 100+ page documents in one call
Reconstructs multi-page tables as unified arrays
Semantic field matching maps "Amount Due", "Grand Total", and "Balance Owed" to the same field
Schema drift detection catches format changes before they break your pipeline
Deep nesting up to 10+ levels
The best part?
Every extracted value links back to its source chunk for traceability.

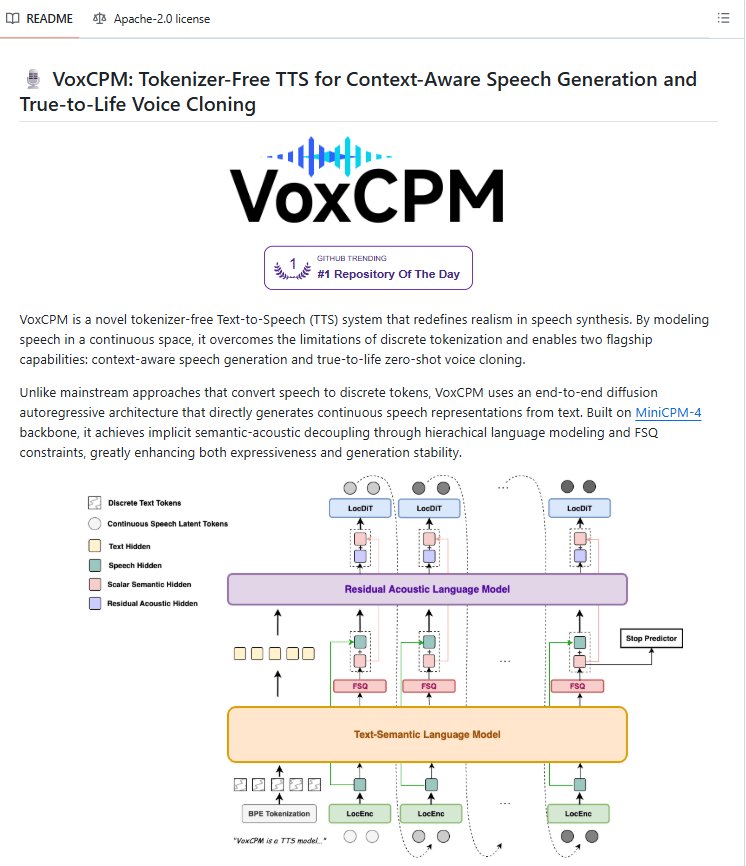
VoxCPM is an open-source, tokenizer-free text-to-speech model. It clones any voice from just 3 seconds of reference audio, capturing accent, rhythm, emotional tone, and pacing.
It is built on an end-to-end diffusion autoregressive architecture on top of MiniCPM-4 and trained on 1.8 million hours of bilingual audio. Instead of compressing speech into tokens, VoxCPM models audio directly in continuous space.
What tokenizer-free actually changes
With 3 seconds of reference audio, the model captures the full texture of how someone speaks. Accent, rhythm, emotional coloring, the natural way their pitch moves.
It also reads the text and infers how it should sound. Explanations slow down naturally. Emphasis lands in the right places. Questions sound like questions.
Fine-tuning and deployment
VoxCPM supports both full fine-tuning and LoRA fine-tuning on your own data. It runs with an RTF of 0.15 on a single NVIDIA RTX 4090 and supports streaming synthesis for real-time applications. Weights are available on HuggingFace under Apache-2.0.
Unsloth now supports GRPO for Gemma 4. You can RL fine-tune Google's latest model on a consumer GPU.
A free Colab notebook from Unsloth is available that walks through the full Sudoku training setup end to end. The model learns through trial and error with reward signals instead of memorizing solutions.
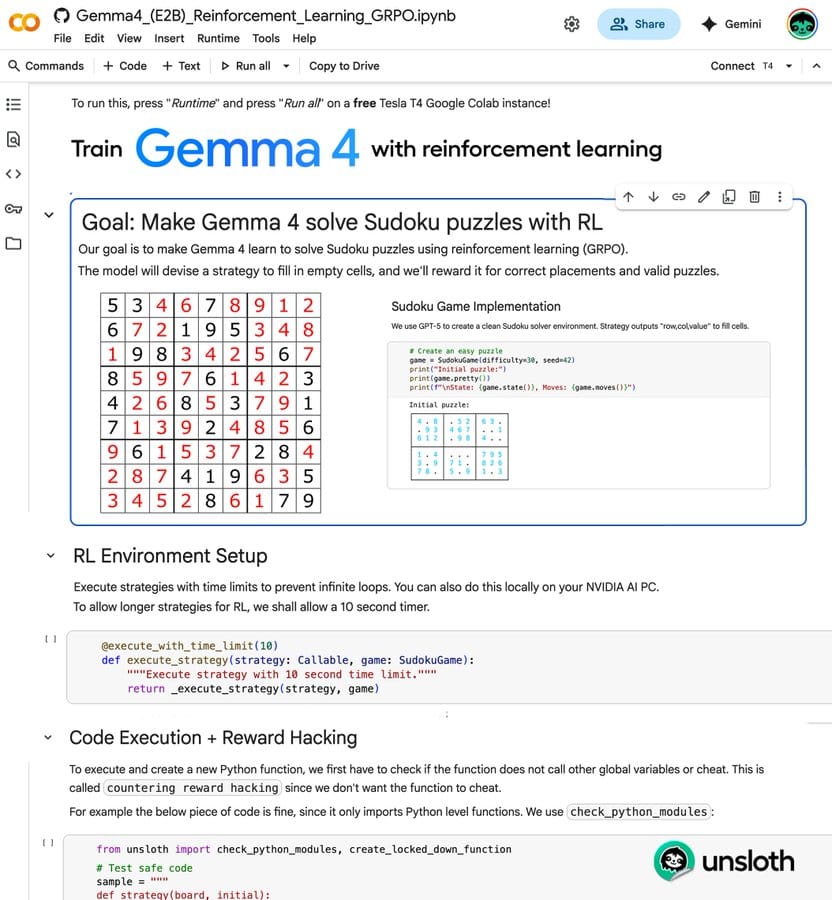
What RL training does differently
Standard fine-tuning teaches models to predict the next word based on examples. RL teaches them to reason through problems by rewarding correct approaches and penalizing wrong ones.
When Gemma 4 places a Sudoku number correctly, it gets a reward. When it violates the rules, it gets penalized. Over many attempts, it learns the actual logic instead of pattern matching.
Why GRPO
GRPO makes this efficient by removing two of the three models traditional PPO needed. It uses statistics from multiple generations instead. The result: you only need 9GB VRAM to run RL training. A single consumer GPU, not a data center.
The workflow
You define what counts as correct. For Sudoku, a valid solved puzzle. For code, passing tests. For math, the right answer. Gemma 4 generates attempts, gets scored, and learns from feedback.
You can apply this to any verifiable task where you can programmatically check correctness.
That’s all for today. Thank you for reading today’s edition. See you in the next issue with more AI Engineering insights.
PS: We curate this AI Engineering content for free, and your support means everything. If you find value in what you read, consider sharing it with a friend or two.
Your feedback is valuable: If there’s a topic you’re stuck on or curious about, reply to this email. We’re building this for you, and your feedback helps shape what we send.
WORK WITH US
Looking to promote your company, product, or service to 200K+ AI developers? Get in touch today by replying to this email.