- AI Engineering
- Posts
- Build Agentic RAG Without Vector Databases
Build Agentic RAG Without Vector Databases
... PLUS: The RL Trick That Teaches Models to Reason, Not Memorize
Sumanth P
April 01, 2026
In today's newsletter:
How PageIndex navigates documents through reasoning, not vectors
Unsloth RL environments replace reward models with verifiable goals
Reading time: 4 minutes.
Vector RAG struggles with structured documents.
Ask a financial chatbot "What was Q3 2025 net revenue?" and it returns chunks containing the word "revenue." Not the specific table cell on page 47. Not the footnote on page 52 that adjusts the number. Just semantically similar text.
The problem: similarity isn't relevance.
How PageIndex works:
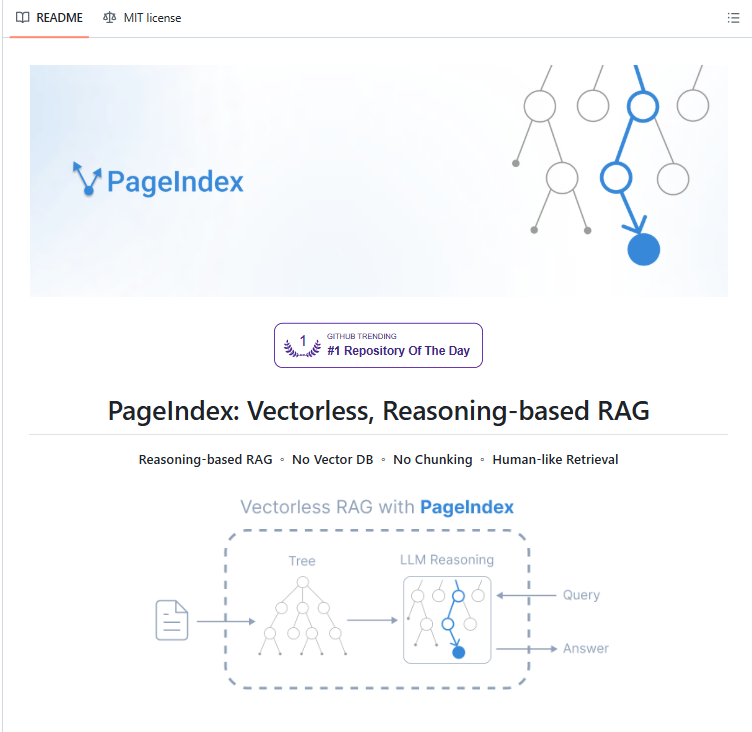
PageIndex builds a hierarchical tree index instead of embeddings. Like an intelligent table of contents with summaries at every level.
Documents get organized into their natural structure: chapters branch into sections, sections into subsections, subsections into paragraphs.
During retrieval, the LLM navigates this tree through reasoning. It reads chapter summaries, picks the relevant branch, drills down to section summaries, continues until it finds the answer.
Example:
Finding revenue in a 10-K filing. You don't read 200 pages. You check the table of contents, find "Financial Statements," navigate to "Income Statement," extract the line item. PageIndex does exactly that.
Why vector chunking fails:
Financial documents are layout-dependent. A table cell with "$4.2B" means nothing without its headers showing which quarter, which metric, which adjustments apply.
PDF-to-text conversion strips structure away. Vector chunking makes it worse by slicing balance sheets into arbitrary blocks. The chunk with "Total Assets: $4.2B" might not include the header saying that's Q3 2025, not Q4 2025. The footnote with adjustments lives elsewhere.
PageIndex preserves the structure.
Results:
Mafin 2.5 (built on PageIndex) hit 98.7% accuracy on FinanceBench. Vector RAG gets 30-50% on the same benchmark.
Every answer includes exact section titles and page numbers. Not vague chunk references.
The tradeoff:
Tree navigation requires multiple LLM calls as the system navigates summaries and drills deeper. Slower and more expensive than single vector searches.
For financial audits or legal contracts where accuracy matters, that works. For speed-critical apps, it doesn't.
When to use it:
Best for: Long, structured documents (SEC filings, legal contracts, technical manuals)
Not for: Multi-document search, unstructured content, speed-critical applications
It’s 100% Open Source
Supervised fine-tuning teaches models to imitate. You show 1,000 examples of how to solve math problems, and the model learns to pattern-match answers.
That works until the real world asks something the training data never covered. The model gets the arithmetic right but fails the logic. It memorized solutions, not reasoning.
Reinforcement learning changes this. Instead of saying "output exactly this," you define a goal and a way to verify it. The model explores reasoning paths, tests different approaches, gets scored on outcomes.
This requires environments.
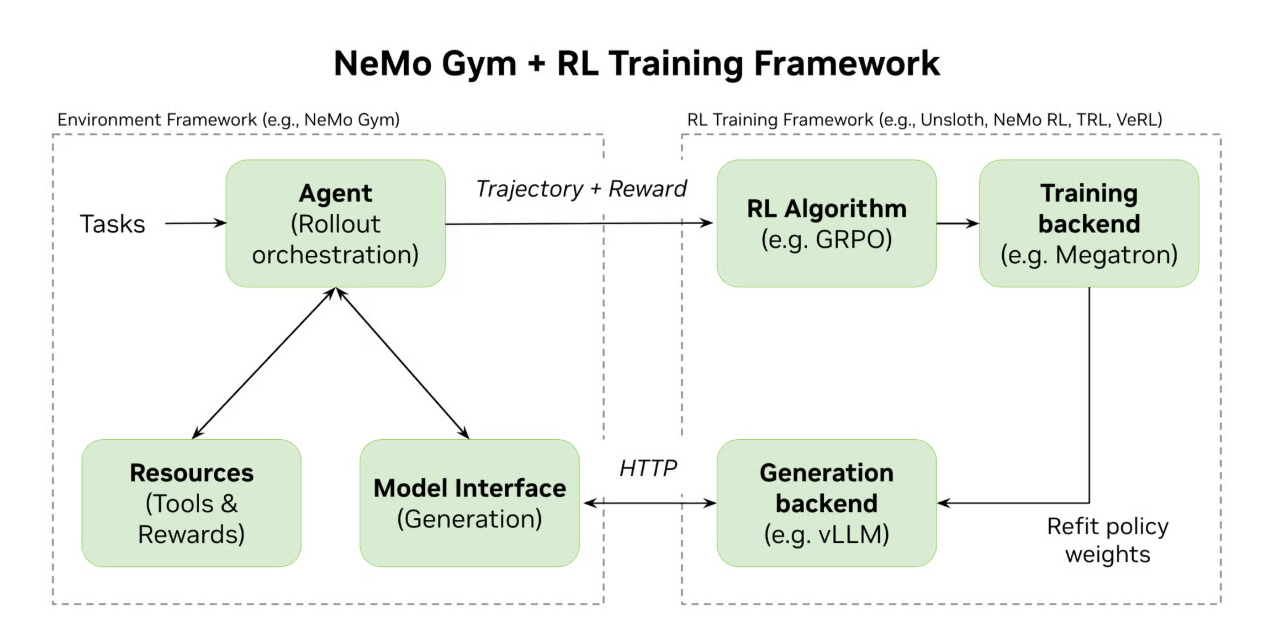
What NeMo Gym does:
NeMo Gym is an open-source library that builds these environments and decouples them from training. You define what success looks like once. Then you can swap optimizers, change hardware, or scale to thousands of parallel rollouts without rewriting environment logic.
The system handles three things:
Agent orchestration (calling the model, executing tool calls, managing the conversation loop)
Resource management (tools, databases, session state for multi-step reasoning)
Verification (scoring whether the agent succeeded)
Unsloth integrates with NeMo Gym for training. HuggingFace TRL and NeMo RL work with it too.
Example environment:
Workplace Assistant gives the agent business requests like "Send an email to John about the meeting tomorrow at 2pm."
The agent must:
Search the database for John's email address
Call the email tool with correct parameters
Verify the email sent successfully
The environment maintains session state across these steps. After the agent finishes, verification checks: did the final database state match the expected outcome?
Binary reward: 1 if correct, 0 if not.
Verification methods:
Four ways to verify agent behavior:
Trajectory matching: Check the exact tool calls and arguments against a golden path. Easy to implement but brittle if multiple solutions exist.
State matching: Check the final outcome regardless of how the agent got there. More robust for complex tasks.
Sandboxed execution: Run generated code against unit tests. Works for coding environments.
LLM-as-judge: Use another LLM to score open-ended outputs. Required when deterministic verification isn't possible.
GRPO efficiency:
Traditional PPO requires a value model and a reward model. GRPO removes both.
It generates groups of outputs, scores them with a verifier (did the code pass tests? is the math answer correct?), and updates the policy based on what worked.
Result: 80% less VRAM than PPO. One model, one training loop.
Real-world use:
Nemotron 3 was trained using NeMo Gym environments. The system refined the model through interactive environments where verification logic prioritized correct tool usage and multi-step reasoning.
Edison Scientific integrated NeMo Gym to train agents that explore scientific hypotheses, run simulations, and receive deterministic feedback from domain-specific environments.
The open challenge:
Most examples focus on math or code because verification is straightforward. For complex real-world tasks, you need rubrics—lists of smaller verifiable sub-rewards rather than one final score.
This works for any task where success is objectively measurable. The challenge: most real-world tasks aren't.
That’s all for today. Thank you for reading today’s edition. See you in the next issue with more AI Engineering insights.
PS: We curate this AI Engineering content for free, and your support means everything. If you find value in what you read, consider sharing it with a friend or two.
Your feedback is valuable: If there’s a topic you’re stuck on or curious about, reply to this email. We’re building this for you, and your feedback helps shape what we send.
WORK WITH US
Looking to promote your company, product, or service to 200K+ AI developers? Get in touch today by replying to this email.