- AI Engineering
- Posts
- Agentic Context Engineering clearly explained
Agentic Context Engineering clearly explained
.. PLUS: Turn Any Website into Agent-Ready Data
Sumanth P
November 15, 2025
In today’s newsletter:
Turn Any Website into Agent-Ready Data
Agentic Context Engineering: The Framework for Self-Improving LLMs
Reading time: 3 minutes.
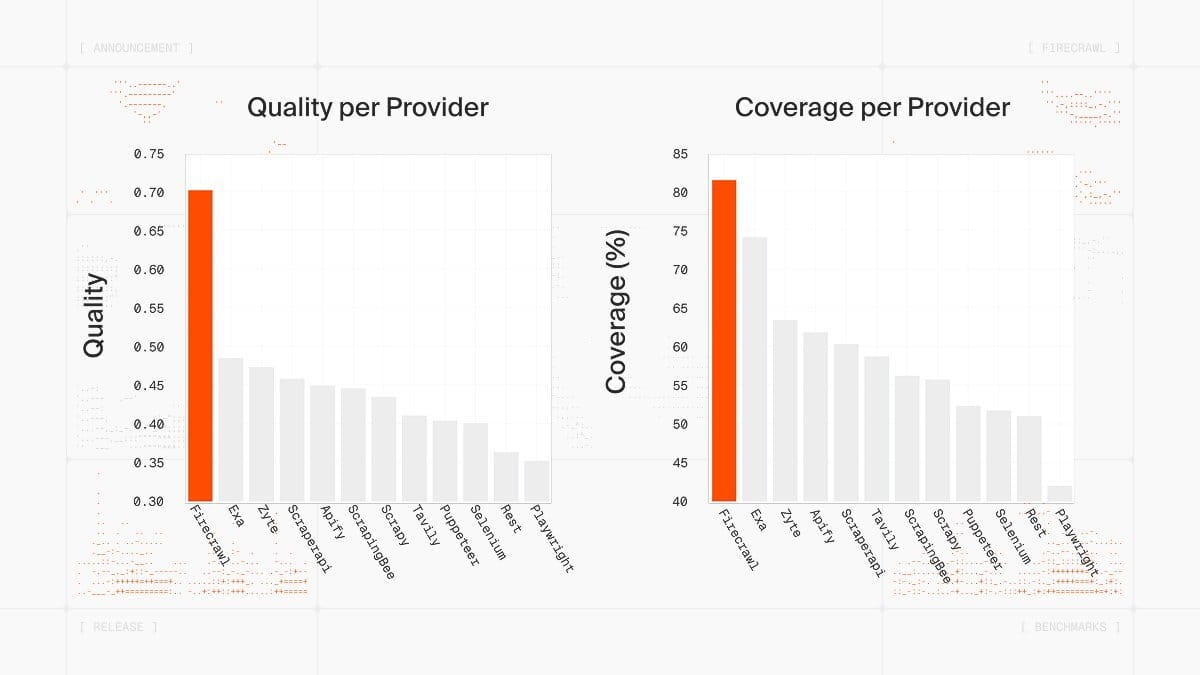
Firecrawl released their new v2.5 endpoint that brings a cleaner way to extract full, reliable page data using a custom browser stack and semantic index.
It figures out how each page is rendered, converts the content into agent-friendly formats, and captures full pages rather than scattered fragments.
The upgraded semantic index stores complete snapshots with embeddings and structure, which makes coverage tighter and retrieval faster.
You can pull data from the live page or from its last verified snapshot, giving you a dependable view of both fresh and historical content.
Key Features:
High-fidelity extraction with custom browser stack
Full-page indexing and agent-ready data formats
Semantic index with 40% API coverage and faster retrieval
Access to current or last-known-good page states
Stanford and SambaNova introduced Agentic Context Engineering (ACE), a framework that allows language models to self-improve without retraining their weights.
Instead of modifying the model, ACE continuously evolves the context layer, which contains the strategies, heuristics and domain knowledge that guide the agent.
Traditional prompt engineering is static. You create a prompt, hope it works, and rewrite it when performance drifts. ACE replaces this with a modular and evolving playbook that improves after every run. This is closer to how human experts refine their workflows by accumulating experience.
ACE directly addresses two common failures in adaptive LLM systems:
Brevity bias: important domain details are lost when prompts are repeatedly summarized or compressed
Context collapse: iterative rewrites deteriorate accumulated strategies and degrade performance over time
ACE avoids these issues by applying incremental updates rather than rewriting the entire prompt.
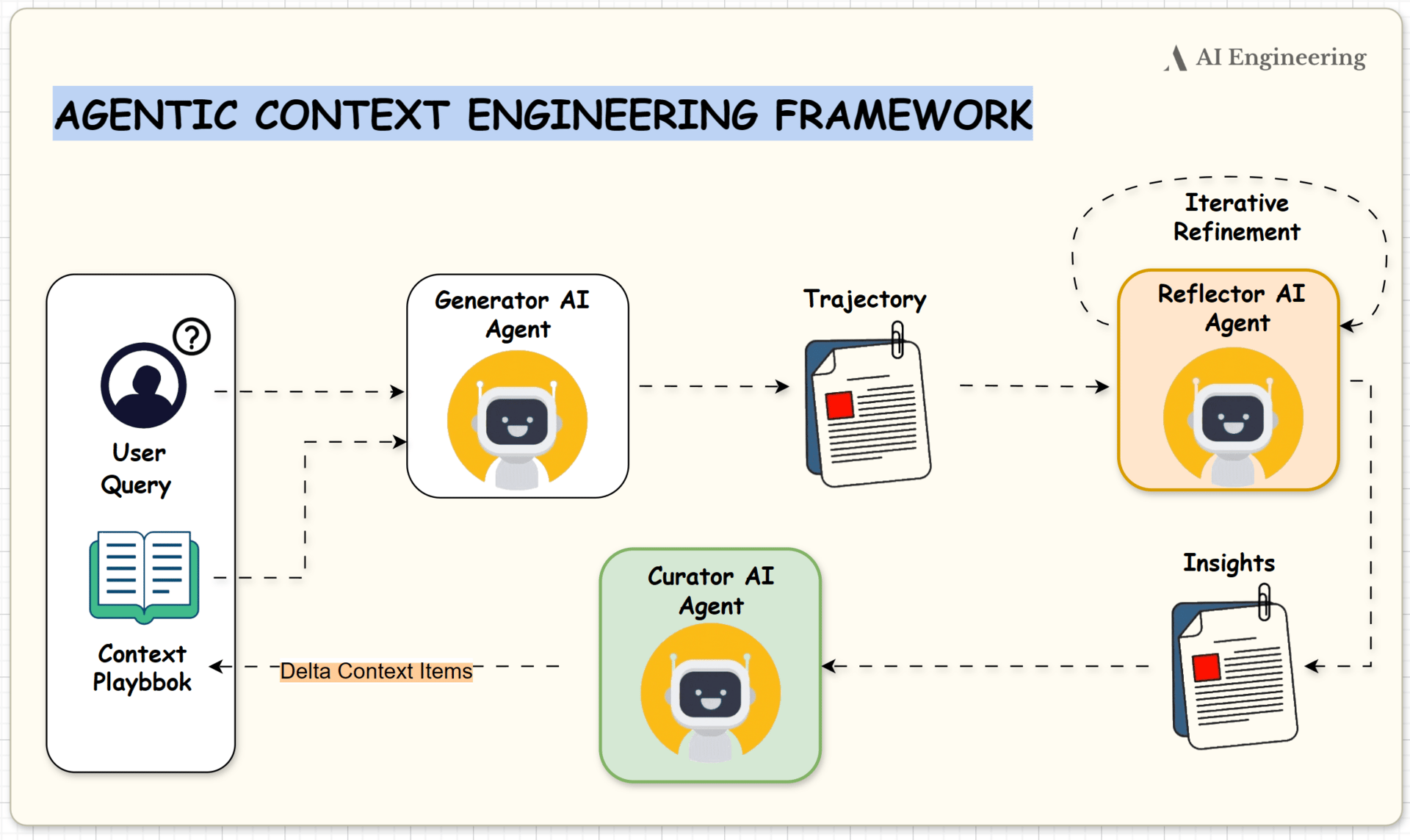
How ACE Works
ACE builds on the Dynamic Cheatsheet memory system and organizes improvement into a structured three-part loop: the Generator, the Reflector and the Curator. Each role contributes a distinct function, creating a continuous cycle of learning without touching model weights.
Generator
The generator captures how the agent approached a task. It produces reasoning traces, action sequences, candidate strategies and general problem solving steps. This gives the system a detailed view of the agent’s decision process rather than only the final output.Reflector
The reflector examines the generator’s traces and determines what succeeded and what failed. It looks for patterns that generalize across tasks, identifies weak or misleading strategies and pinpoints the reasoning paths that consistently produce strong results. This step distills useful insights from raw execution data.Curator
The curator incorporates these insights into the evolving context. It creates small and targeted delta updates that add refined strategies, remove low value or redundant items and reorganize the playbook into a clean and structured form. The curator ensures that knowledge grows without noise or drift.
Together, these components maintain a living playbook that becomes more specialized and more reliable with every task.
Key Features:
Agentic Workflow – separates generation, reflection, and curation into distinct roles for structured adaptation.
Incremental Delta Updates – replaces full prompt rewrites with localized edits to preserve accumulated knowledge.
Grow-and-Refine Mechanism – adaptively expands context while pruning redundant entries for scalability.
Self-Improvement via Feedback – learns directly from execution results without labeled data.
Efficiency at Scale – reduces cost and latency by over 80% through lightweight, non-LLM merging operations.
Key Results:
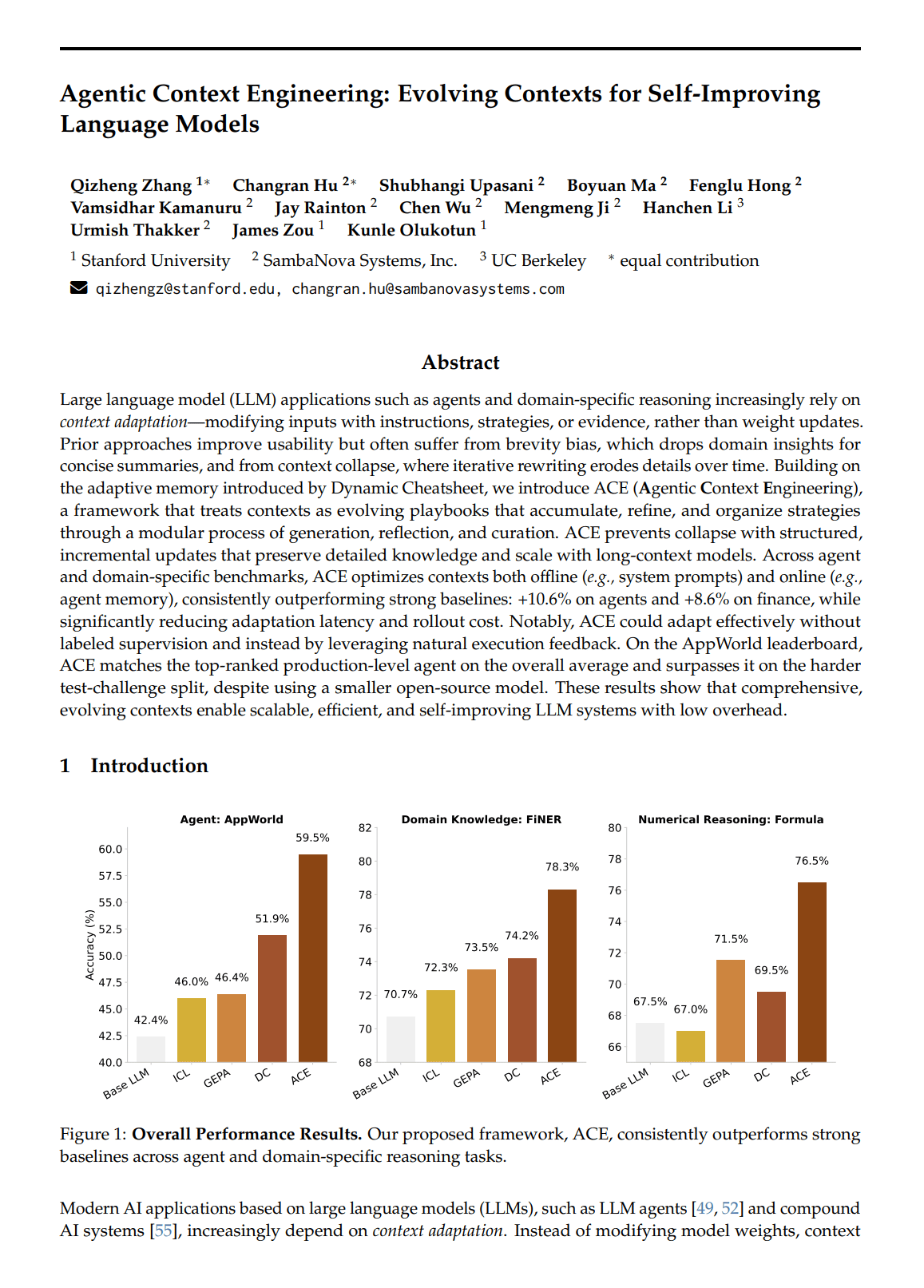
ACE was evaluated on both agent benchmarks and domain specific tasks.
10.6 percent improvement on AppWorld agent tasks
8.6 percent improvement on financial reasoning tasks such as FiNER and Formula
86.9 percent lower adaptation latency and 83 percent lower compute cost compared to earlier adaptation methods
Matched the performance of the GPT 4.1 based IBM CUGA agent while using a smaller open model, DeepSeek V3.1
Achieved effective adaptation using only natural execution feedback and no supervised labels
These results show that high quality adaptation is possible without model fine tuning.
Why It Matters:
ACE transforms context engineering from a static prompt into a dynamic learning process. The agent continually generates new insights, reflects on performance, and refines its own context. The underlying weights remain unchanged, yet the system grows more capable through experience.
Larger context windows and improved KV caching make this approach increasingly practical for production use cases. ACE provides a path toward self improving LLM agents that adapt to domains, tools and workflows without retraining.
That’s a Wrap
That’s all for today. Thank you for reading today’s edition. See you in the next issue with more AI Engineering insights.
PS: We curate this AI Engineering content for free, and your support means everything. If you find value in what you read, consider sharing it with a friend or two.
Your feedback is valuable: If there’s a topic you’re stuck on or curious about, reply to this email. We’re building this for you, and your feedback helps shape what we send.
WORK WITH US
Looking to promote your company, product, or service to 160K+ AI developers? Get in touch today by replying to this email.