- AI Engineering
- Posts
- 8 LLM Architectures clearly explained
8 LLM Architectures clearly explained
.. PLUS: Agent Endpoint for web data search
Sumanth P
December 29, 2025
In today’s newsletter:
Agent Endpoint for web data search
8 LLM Architectures, clearly explained
Reading time: 5 minutes.
Firecrawl released their new /agent endpoint that searches, navigates, and gathers data from the widest range of websites.
Instead of providing URLs upfront, you describe what you’re looking for and the agent handles discovery, navigation, and extraction across relevant sources.
Key Features:
No URLs Required: Just describe what you need via
promptparameter. URLs are optional.Deep Web searches and navigates deep into sites to find your data
Works with a wide variety of queries and use cases
Processes multiple sources in parallel for quicker results
Example Use Cases:
Market research: Extract recent funding details for AI startups from company and press pages.
Competitive analysis: Compare pricing tiers and features across Slack and Microsoft Teams pages.
Data collection: Pull contact emails and support links from company websites.
Firecrawl is also giving 1,000 free credits to test the agent endpoint, available on a first-come basis. Use the code “AIENGINEERING” to access them.

8 Types of LLM Architectures
LLMs are no longer a single model type with different sizes. Most modern systems combine multiple architectural ideas depending on what they are optimizing for: reasoning depth, cost, latency, multimodality, or action execution.
When you build AI products or agents, model choice is an architectural decision, not just a benchmark comparison. Different tasks benefit from very different model designs.
Below are eight LLM architecture patterns you will commonly encounter in production systems, along with what they are optimized for and where they fit best.
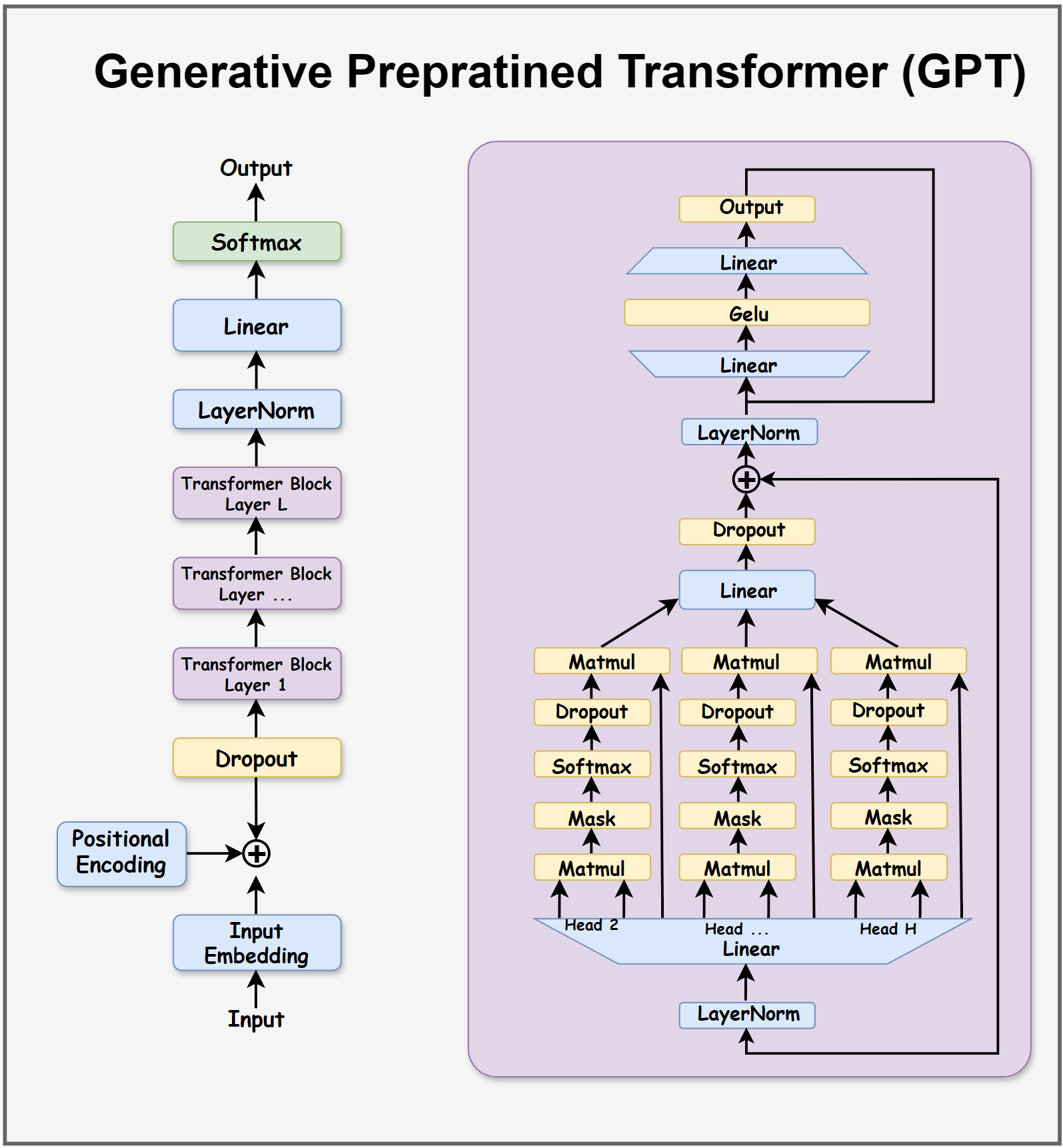
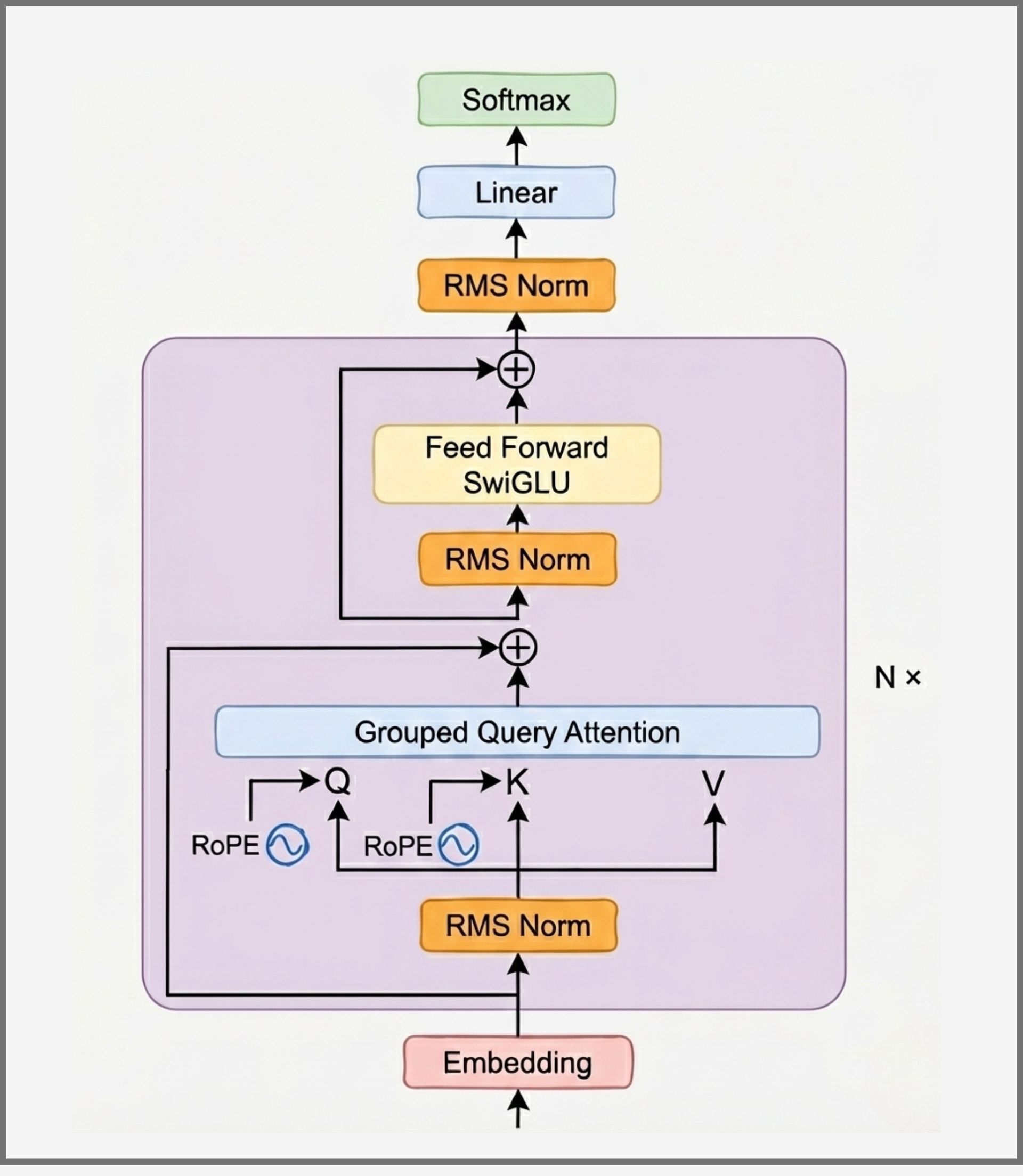
1. Generative Pretrained Transformer (GPT)
GPT-style models are decoder-only Transformers trained with a causal language modeling objective: predicting the next token given previous tokens.
They use masked self-attention so each token can only attend to earlier tokens, enforcing left-to-right generation. Training focuses on learning general language patterns from large text corpora, followed by fine-tuning or instruction tuning for specific tasks.
This architecture is simple, scalable, and highly optimized for text generation, making it the default choice for chat models, coding assistants, and general-purpose LLMs.
Best suited for: conversational AI, code generation, summarization, general language tasks.
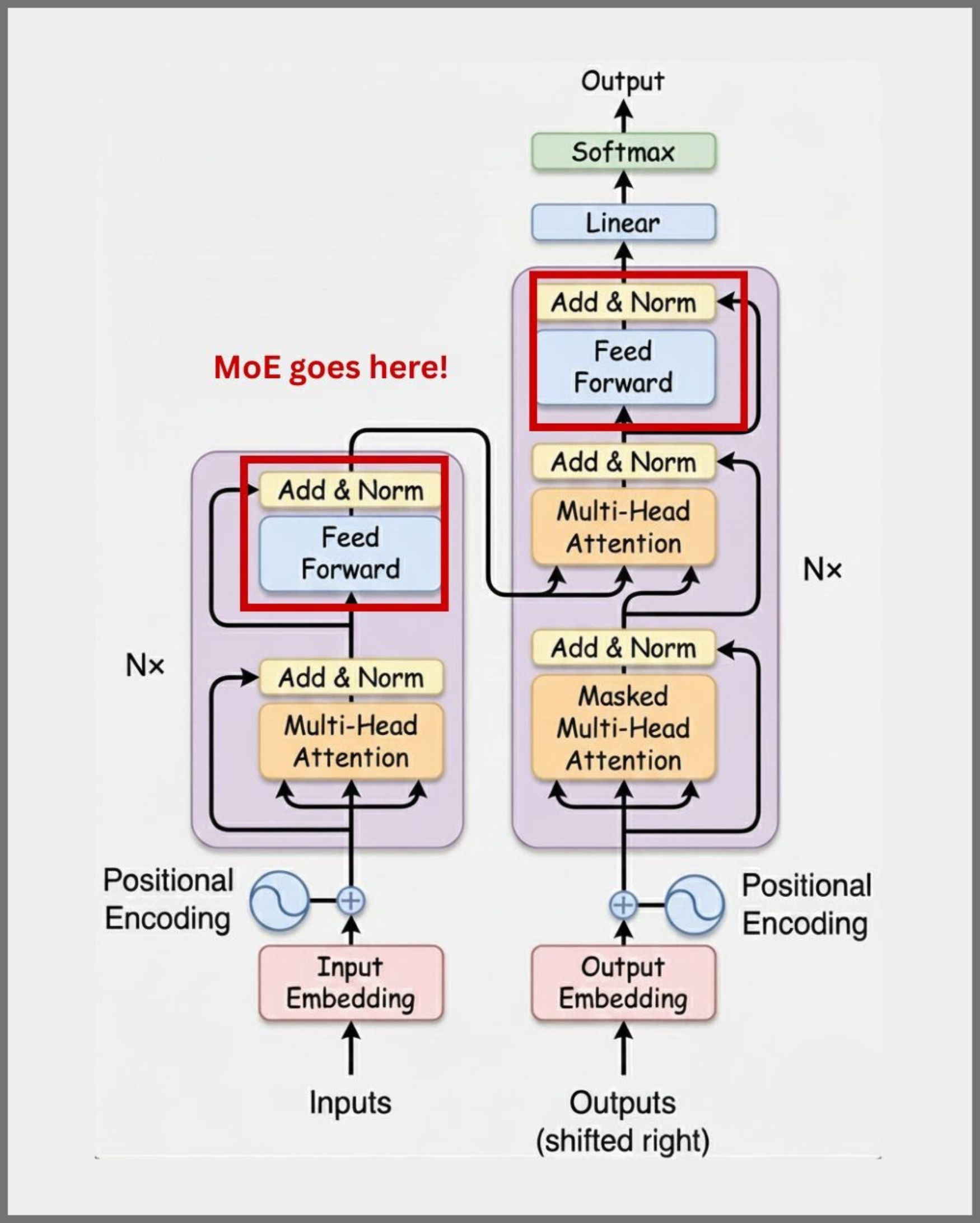
2. Mixture of Experts (MoE)
MoE architectures introduce sparse computation by routing each token to a small subset of expert feed-forward networks instead of activating the full model.
A learned router selects the top-k experts per token, so only those experts run. This allows models to scale to very large parameter counts without proportional increases in compute cost.
MoE improves throughput and cost efficiency, especially at scale, but introduces complexity in training stability and routing balance.
Best suited for: large-scale LLMs, multilingual models, cost-sensitive high-throughput systems.
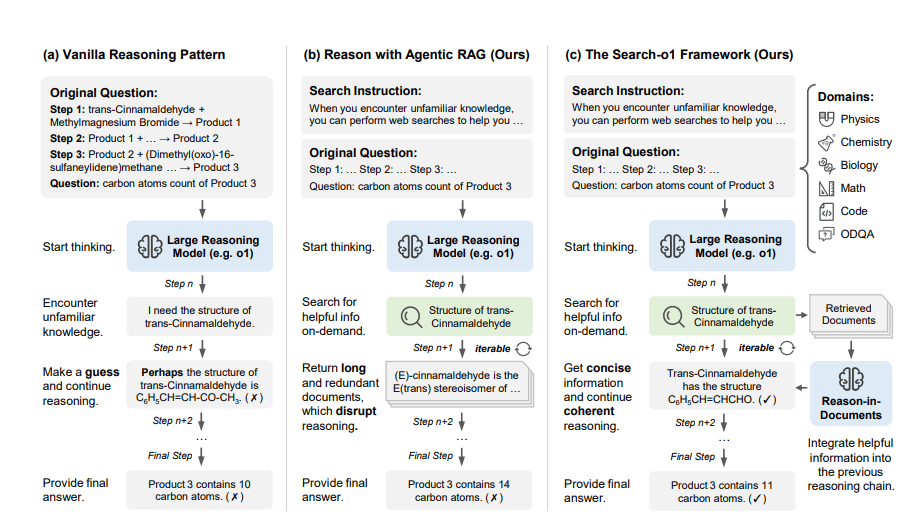
3. Large Reasoning Model (LRM)
Large Reasoning Models are not defined by structure alone, but by reasoning-centric training. They are typically Transformer-based models trained with techniques such as chain-of-thought supervision, reinforcement learning, or self-consistency.
These models explicitly generate intermediate reasoning steps before producing final answers, improving performance on complex logic, math, planning, and multi-step problem solving.
LRMs trade latency and verbosity for better reasoning reliability.
Best suited for: math reasoning, code debugging, scientific analysis, agent planning.
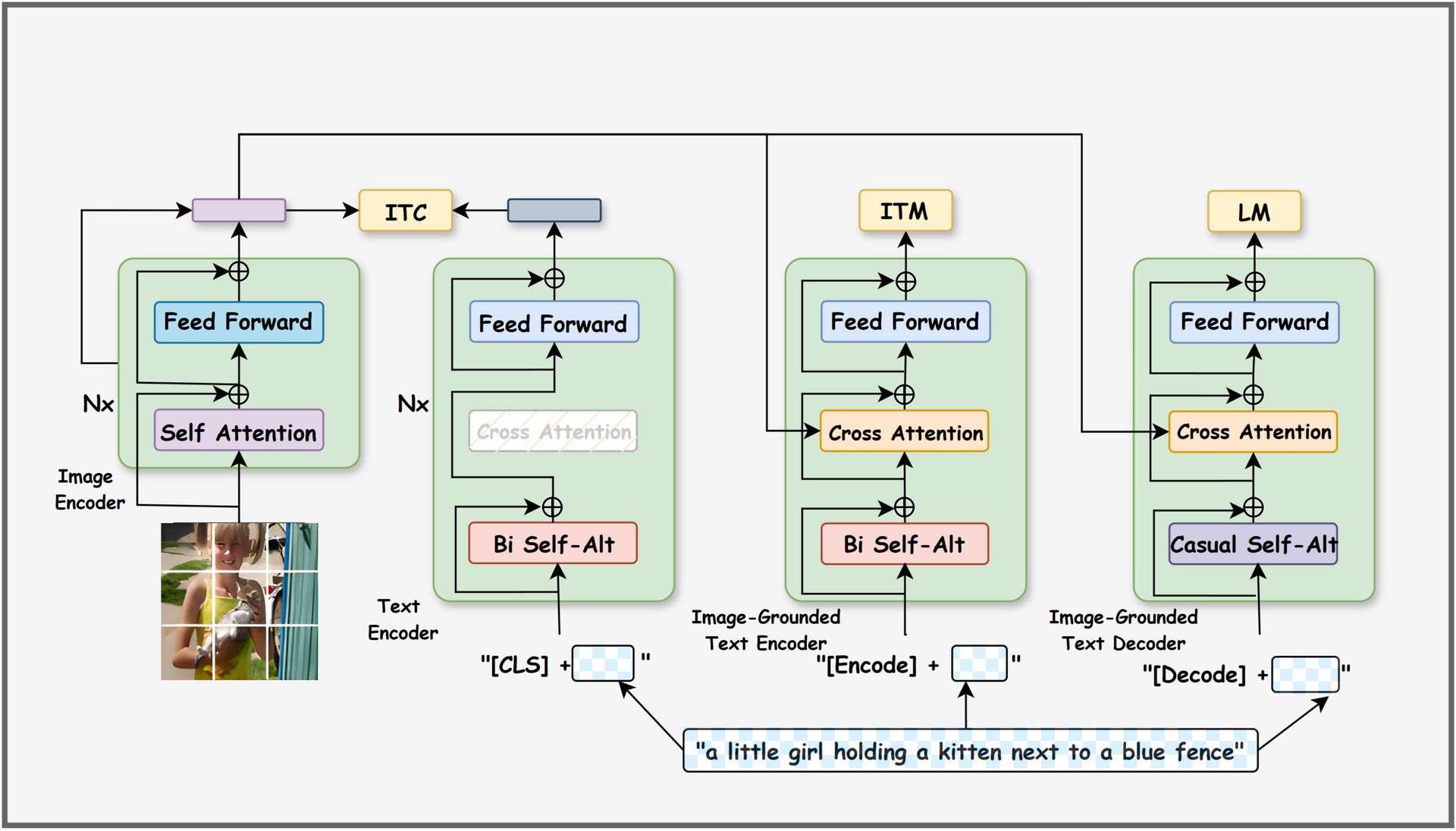
4. Vision-Language Model (VLM)
VLMs combine visual and textual understanding by aligning image and text representations.
They typically use a vision encoder (such as a Vision Transformer) and a text encoder or decoder, with visual features projected into the language embedding space. Fusion happens through cross-attention or token concatenation.
Pretraining on large image-text datasets enables strong zero-shot and few-shot multimodal reasoning.
Best suited for: document understanding, visual Q&A, multimodal agents, accessibility tools.
5. Small Language Model (SLM)
SLMs focus on efficiency rather than scale. They use architectural optimizations such as grouped-query attention, smaller hidden dimensions, and reduced layer counts.
Training often relies on knowledge distillation from larger models. Quantization and pruning further reduce memory and compute requirements.
SLMs enable fast, low-latency inference and are often deployed on edge devices or in real-time systems.
Best suited for: mobile applications, on-device inference, edge and IoT workloads.
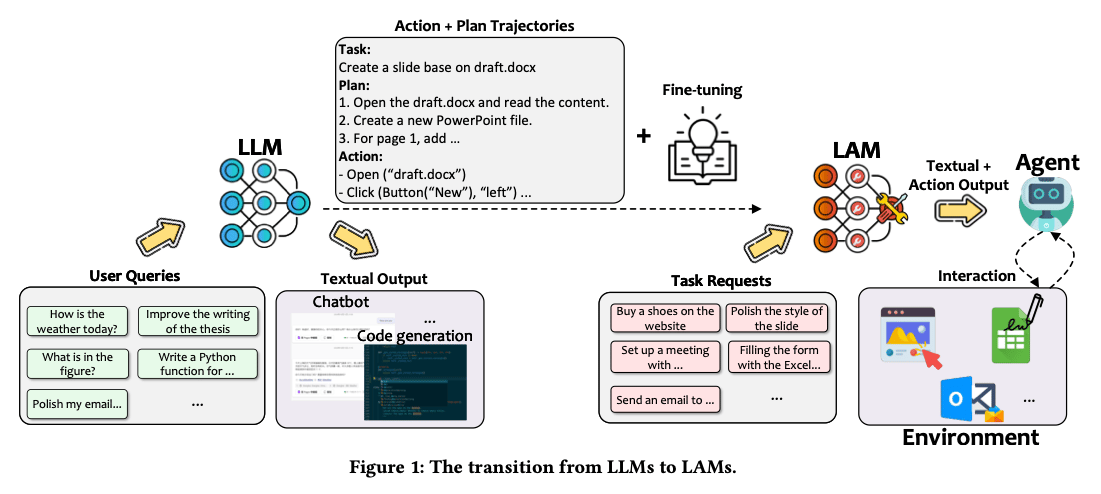
6. Large Action Model (LAM)
LAMs build upon the foundational capabilities of LLMs but are specifically optimized for action-oriented tasks.
They generate structured outputs (such as JSON) that specify tool calls, API parameters, or actions. These outputs are executed by external runtimes, and results are fed back into the model in a perception–reason–act loop.
This architecture enables intent-to-action translation and closed-loop control.
Best suited for: autonomous agents, API automation, software workflows, robotics control.
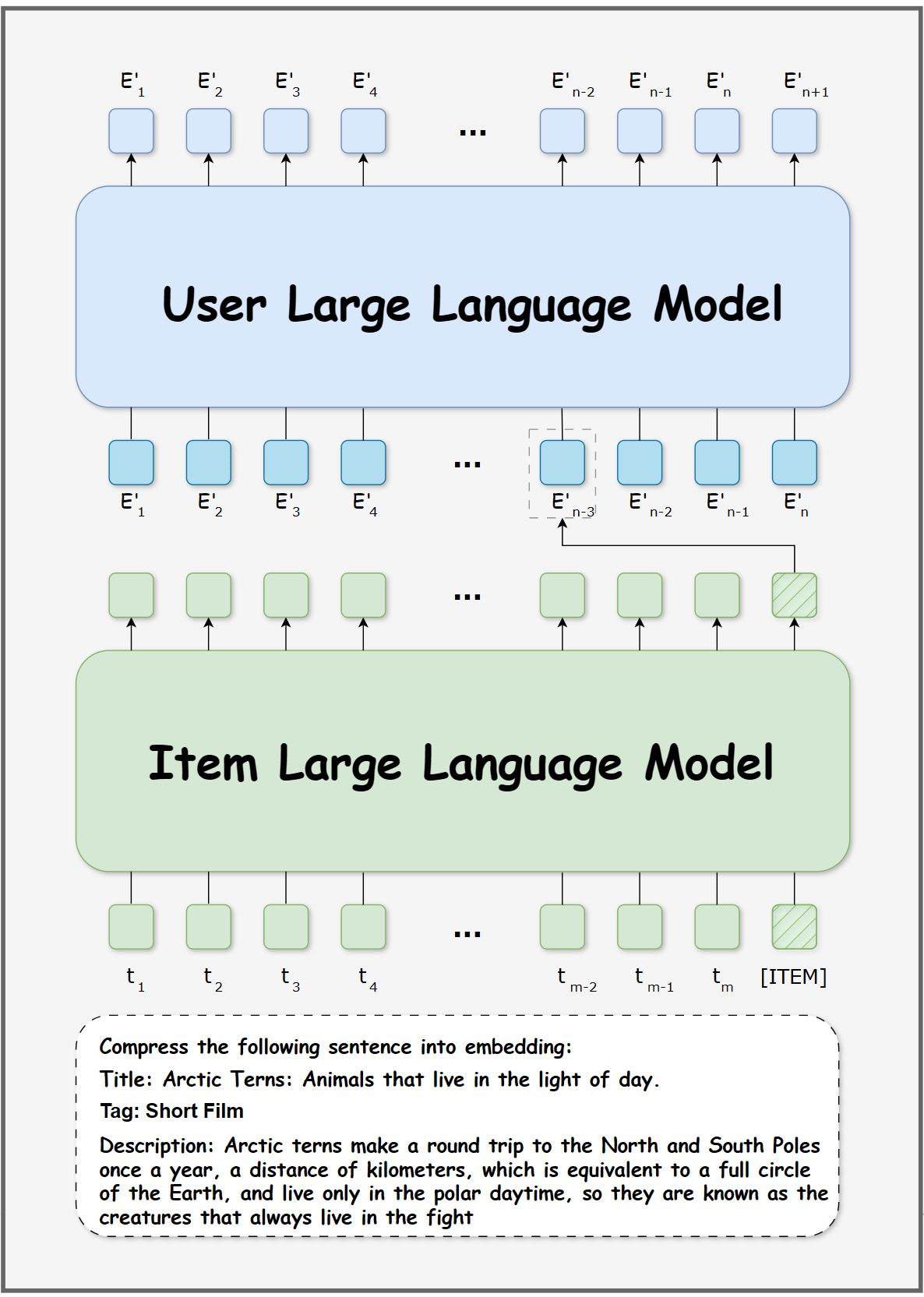
7. Hierarchical Language Model (HLM)
HLMs introduce hierarchical control, separating high-level planning from low-level execution.
Higher layers handle goal setting and task decomposition, while lower layers focus on execution. Communication between layers uses structured representations rather than raw text.
This improves long-horizon planning, reduces error propagation, and allows reuse of high-level logic.
Best suited for: long-running workflows, multi-turn agents, project planning systems.
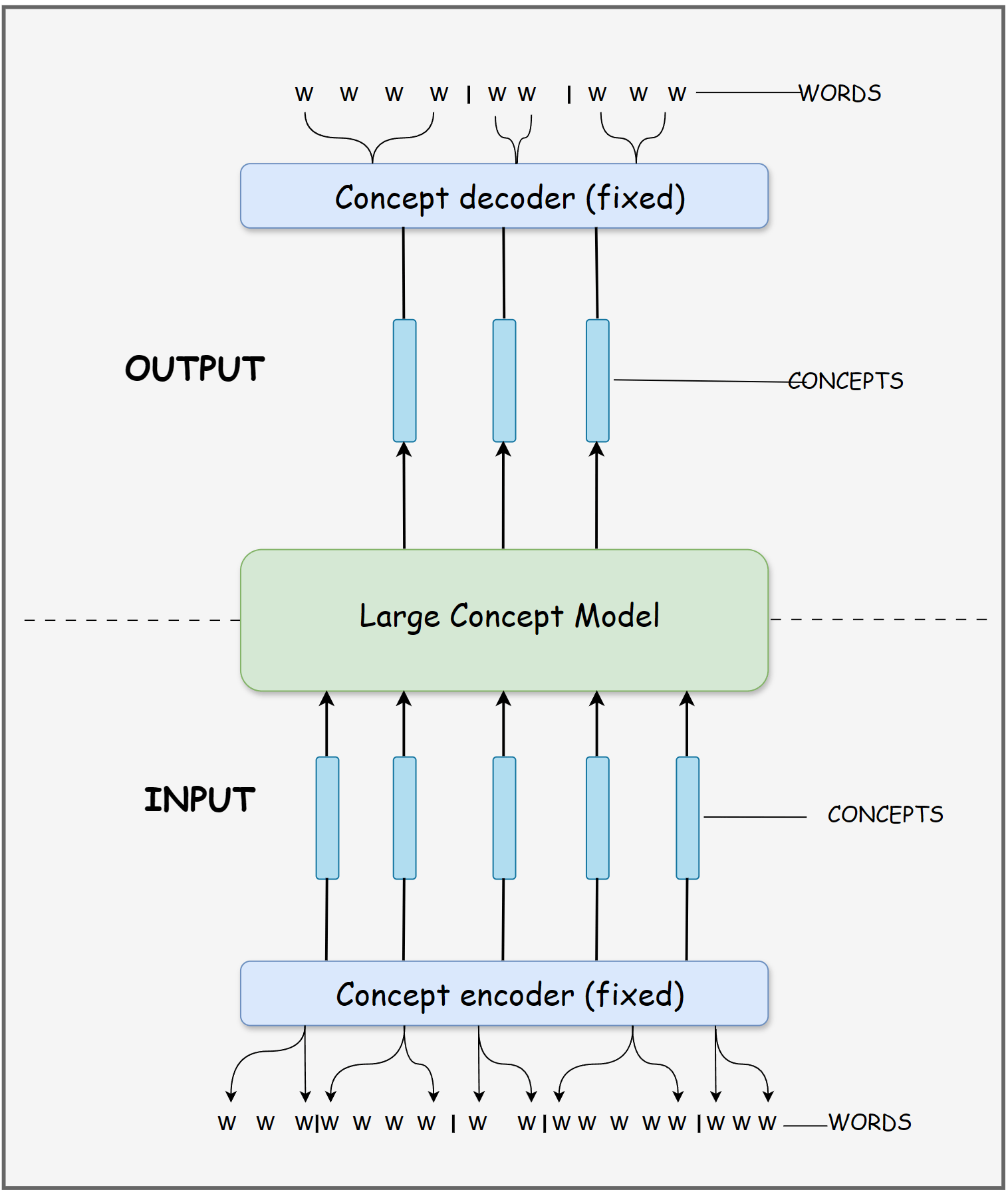
8. Large Concept Model (LCM)
Large Concept Models focus on concept-level representations rather than token-level prediction.
Instead of modeling language purely as sequences of tokens, these systems represent knowledge as higher-level concepts and relationships, often using graph-based structures. Reasoning operates over concepts and their connections rather than surface text patterns.
This approach aims to improve generalization across paraphrases, domains, and languages by reasoning over abstract relationships instead of raw text.
At present, LCMs are primarily a research direction rather than a widely deployed production architecture. Most implementations exist in academic or experimental systems, and they are often explored in combination with neural language models rather than as standalone replacements.
Best suited for: scientific reasoning, knowledge synthesis, and research-oriented systems.
These eight architectures represent the main design patterns behind modern GenAI systems.
They are not mutually exclusive. Many real-world systems combine multiple approaches depending on constraints like cost, latency, reasoning depth, and action execution.
Understanding these architectural differences helps you choose the right model for a task, design more reliable agent systems, and avoid treating all LLMs as interchangeable components when moving from prototypes to production.
That’s a Wrap
That’s all for today. Thank you for reading today’s edition. See you in the next issue with more AI Engineering insights.
PS: We curate this AI Engineering content for free, and your support means everything. If you find value in what you read, consider sharing it with a friend or two.
Your feedback is valuable: If there’s a topic you’re stuck on or curious about, reply to this email. We’re building this for you, and your feedback helps shape what we send.
WORK WITH US
Looking to promote your company, product, or service to 160K+ AI developers? Get in touch today by replying to this email.